Welcome to the Machine
This is Not A Drill
Welcome to the Machine
Welcome to the Machine
This is Not A Drill
Welcome to the Machine
Data
Data
Data
Normalization
Normalization
Normalization
with
with
with
Unbreakable
Unbreakable
Unbreakable
Security
Security
Security
Effortlessly transition to SAP S/4HANA with QIQ Orchestrate while safeguarding your
critical data with QuantumIQ’s next-gen ransomware protection.
Effortlessly transition to SAP S/4HANA with QIQ Orchestrate while safeguarding your
critical data with QuantumIQ’s next-gen ransomware protection.
Effortlessly transition to SAP S/4HANA with QIQ Orchestrate while safeguarding your critical data with QuantumIQ’s next-gen ransomware protection.
Powered by
Powered by
Bloom with
Bloom with
QIQ Orchestrater
QIQ Orchestrater
QIQ Orchestrate simplifies the transition to SAP S/4HANA with deep integration and automation, ensuring a smooth migration with minimal disruption.
QIQ Orchestrate simplifies the transition to SAP S/4HANA with deep integration and automation, ensuring a smooth migration with minimal disruption.
Bloom with
QIQ Orchestrater
QIQ Orchestrate simplifies the transition to SAP S/4HANA with deep integration and automation, ensuring a smooth migration with minimal disruption.

End-to-End Data Connectivity
End-to-End Data Connectivity
End-to-End Data Connectivity
Connect directly to SAP environments or ingest static snapshots via our AWS-hosted platform.
Connect directly to SAP environments or ingest static snapshots via our AWS-hosted platform.
Automated Data Transformation
Automated Data Transformation
Automated Data Transformation
Clean, rename, join, and filter data for a structured and optimized migration.
Clean, rename, join, and filter data for a structured and optimized migration.
Effortless Migration
Effortless Migration
Effortless Migration
Export transformed data seamlessly into S/4HANA using our software-defined data integration (SDDI) model.
Export transformed data seamlessly into S/4HANA using our software-defined data integration (SDDI) model.
Flexible & Scalable
Flexible & Scalable
Flexible & Scalable
Migrate post-initialization or pre-package data for deployment, handling organizations of any size.
Migrate post-initialization or pre-package data for deployment, handling organizations of any size.
QuantumIQ
QuantumIQ
Fallout Shelter
Fallout Shelter
Ransomware protection is a core feature of the Foundry platform and all QuantumIQ products. We've expanded this security into a fully automated data enclave with built-in alerting and resistance to social engineering attacks.
Ransomware protection is a core feature of the Foundry platform and all QuantumIQ products. We've expanded this security into a fully automated data enclave with built-in alerting and resistance to social engineering attacks.
QuantumIQ
Fallout Shelter
Ransomware protection is a core feature of the Foundry platform and all QuantumIQ products. We've expanded this security into a fully automated data enclave with built-in alerting and resistance to social engineering attacks.
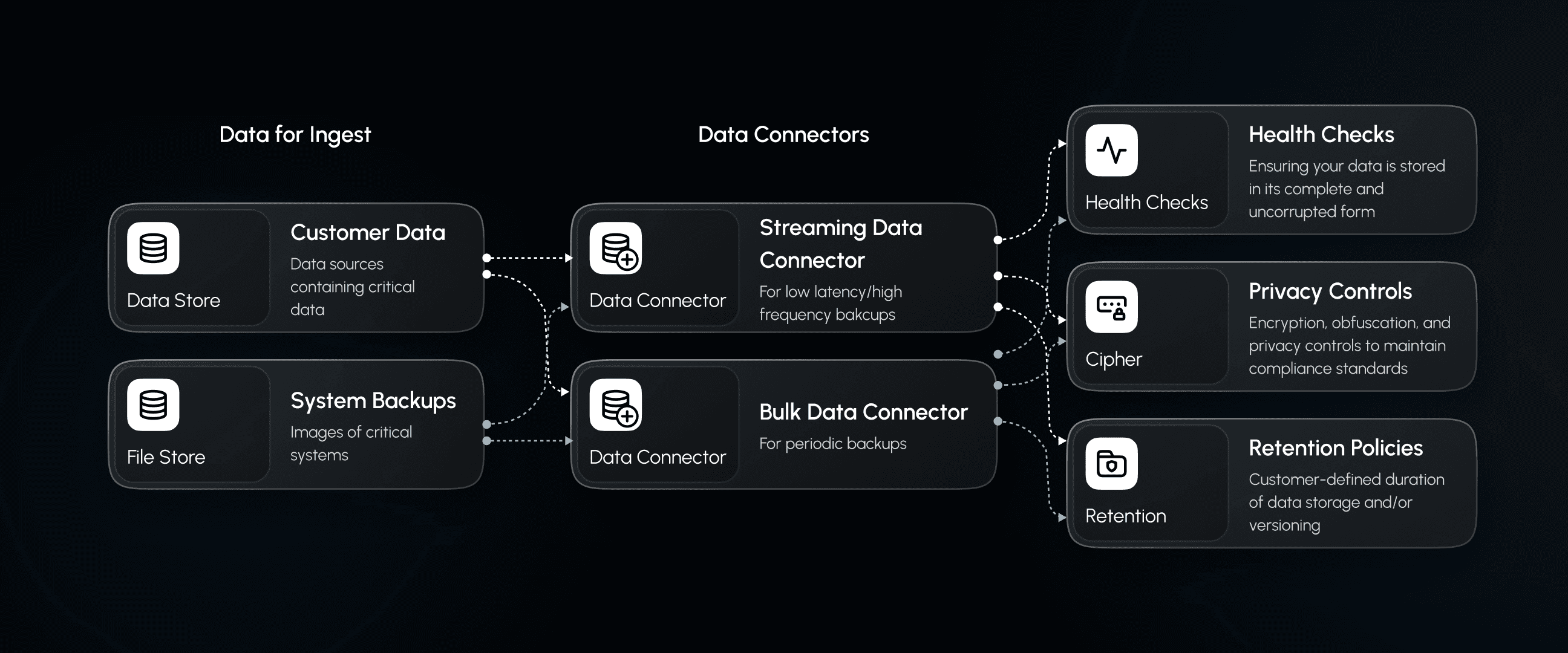
Immutable Data Protection
Immutable Data Protection
A secure, versioned "digital twin" of your data ensures rapid recovery from ransomware attacks without operational downtime.
Seamless Data Connectivity
Seamless Data Connectivity
Access over 150 native connectors within Palantir Foundry to integrate structured, unstructured, and semi-structured data sources.
Immutable Data Protection
A secure, versioned "digital twin" of your data ensures rapid recovery from ransomware attacks without operational downtime.
Seamless Data Connectivity
Access over 150 native connectors within Palantir Foundry to integrate structured, unstructured, and semi-structured data sources.
Decoupled Security Architecture
Decoupled Security Architecture
Eliminate single-points-of-failure with role-based access controls, granular data permissions, and time-restricted user access.
Dual-Layer Authentication
Dual-Layer Authentication
Owner credentials are split between the customer and QuantumIQ, ensuring no single entity can compromise protected data.
Decoupled Security Architecture
Eliminate single-points-of-failure with role-based access controls, granular data permissions, and time-restricted user access.
Dual-Layer Authentication
Owner credentials are split between the customer and QuantumIQ, ensuring no single entity can compromise protected data.
Exit with
Exit with
QIQ Orchestrater
QIQ Orchestrater
Migrating between virtual machine providers and environments can be resource-intensive, straining the balance between time and cost. QIQ Orchestrate streamlines this process with an intuitive, repeatable software pipeline that adapts to your organization’s needs.
Migrating between virtual machine providers and environments can be resource-intensive, straining the balance between time and cost. QIQ Orchestrate streamlines this process with an intuitive, repeatable software pipeline that adapts to your organization’s needs.
Exit with
QIQ Orchestrater
Migrating between virtual machine providers and environments can be resource-intensive, straining the balance between time and cost. QIQ Orchestrate streamlines this process with an intuitive, repeatable software pipeline that adapts to your organization’s needs.
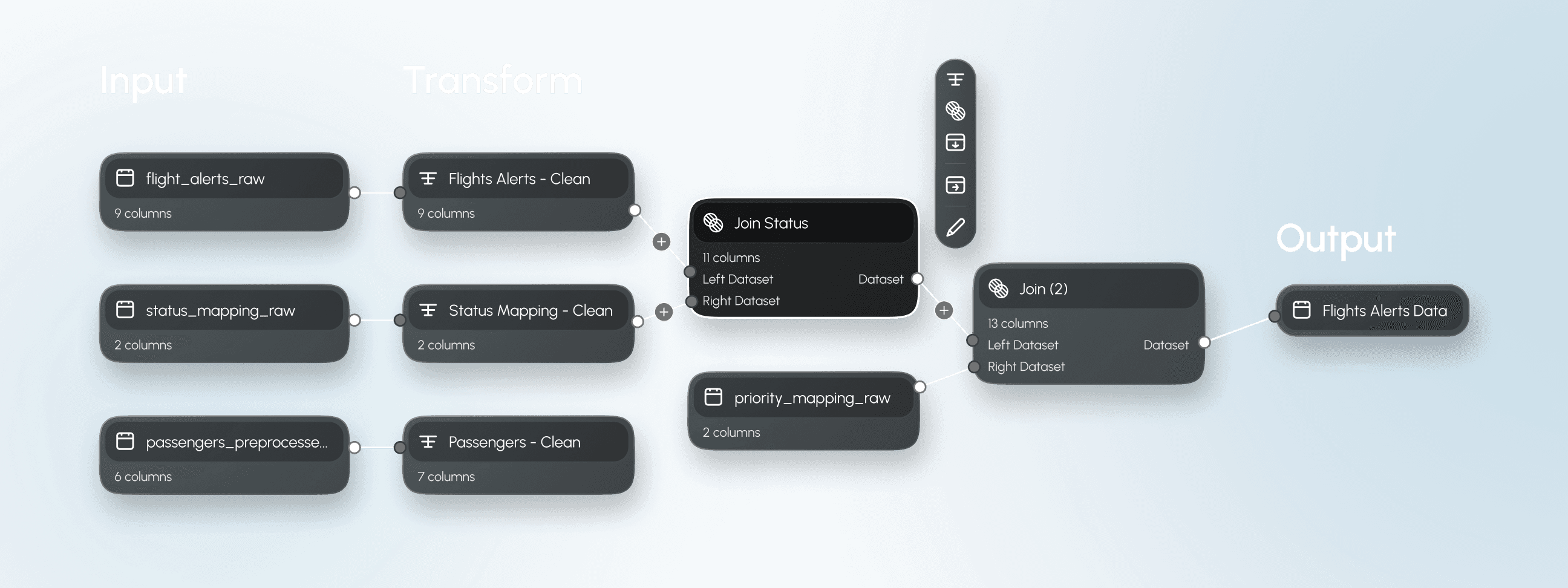
Comprehensive Data Connectivity
Comprehensive Data Connectivity
Connect seamlessly to 150+ native enterprise data sources, including cloud storage, databases, and data warehouses.
Automated & Scalable Pipelines
Automated & Scalable Pipelines
Reusable, extensible pipelines simplify VM migration across fractured versions and diverse environments.
Comprehensive Data Connectivity
Connect seamlessly to 150+ native enterprise data sources, including cloud storage, databases, and data warehouses.
Automated & Scalable Pipelines
Reusable, extensible pipelines simplify VM migration across fractured versions and diverse environments.
Customizable Migration Workflows
Customizable Migration Workflows
Tailor data transfer and configuration mapping to match your specific infrastructure requirements.
Parallel Execution for Efficiency
Parallel Execution for Efficiency
Scale migrations effortlessly by executing workflows concurrently across multiple VMs.
Customizable Migration Workflows
Tailor data transfer and configuration mapping to match your specific infrastructure requirements.
Parallel Execution for Efficiency
Scale migrations effortlessly by executing workflows concurrently across multiple VMs.
Hydrate the Ontology
Hydrate the Ontology
Integration with purpose: combine your data, models, and processes into a dynamic foundation.
Hydrate the Ontology
Integration with purpose: combine your data, models, and processes into a dynamic foundation.
Activate the Ontology
Activate the Ontology
Transform myriad data and models into dynamic, real-world objects, relations, actions, and more.
Activate the Ontology
Transform myriad data and models into dynamic, real-world objects, relations, actions, and more.
Wield the Ontology
Wield the Ontology
Build scalable, sophisticated workflows with speed and stability for an ever-changing world.
Wield the Ontology
Build scalable, sophisticated workflows with speed and stability for an ever-changing world.
QIQ Pathology
QIQ Pathology
Secure Data Enclaves with Federated Data Access
Secure Data Enclaves with Federated Data Access
Unified Access
Unified Access
Federated data across stacks via 200+ connectors. Central web portal preserves ownership.
Granular Security
Granular Security
Role-based controls mask PHI in all data types.
Full Auditing
Full Auditing
Logs track every access, movement, and export.
QuantumIQ’s QIQ Pathology, built on the Palantir Foundry platform, delivers a unified federated data access solution that balances strong security with seamless usability. It enables collaboration across diverse technology stacks while preserving data ownership for each entity.
QuantumIQ’s QIQ Pathology, built on the Palantir Foundry platform, delivers a unified federated data access solution that balances strong security with seamless usability. It enables collaboration across diverse technology stacks while preserving data ownership for each entity.
With over 200 data connectors, users can securely access and manage data from disparate sources through a centralized, web-based portal. Role- and purpose-based access controls ensure users see only the data they need, when they need it.
With over 200 data connectors, users can securely access and manage data from disparate sources through a centralized, web-based portal. Role- and purpose-based access controls ensure users see only the data they need, when they need it.
Advanced tools identify and obfuscate sensitive information—including PHI and media files—to prevent re-identification risks. Comprehensive audit logs and strict identity policies monitor every access and data movement, with tightly controlled export capabilities.
Advanced tools identify and obfuscate sensitive information—including PHI and media files—to prevent re-identification risks. Comprehensive audit logs and strict identity policies monitor every access and data movement, with tightly controlled export capabilities.
QIQ Pathology empowers organizations and collaborative groups to securely govern and share data, delivering best-in-class privacy and security from a cloud-based SaaS platform.
QIQ Pathology empowers organizations and collaborative groups to securely govern and share data, delivering best-in-class privacy and security from a cloud-based SaaS platform.
QIQ Pathology
Secure Data Enclaves with Federated Data Access
Unified Access
Federated data across stacks via 200+ connectors. Central web portal preserves ownership.
Granular Security
Role-based controls mask PHI in all data types.
Full Auditing
Logs track every access, movement, and export.
QuantumIQ’s QIQ Pathology, built on the Palantir Foundry platform, delivers a unified federated data access solution that balances strong security with seamless usability. It enables collaboration across diverse technology stacks while preserving data ownership for each entity.
With over 200 data connectors, users can securely access and manage data from disparate sources through a centralized, web-based portal. Role- and purpose-based access controls ensure users see only the data they need, when they need it.
Advanced tools identify and obfuscate sensitive information—including PHI and media files—to prevent re-identification risks. Comprehensive audit logs and strict identity policies monitor every access and data movement, with tightly controlled export capabilities.
QIQ Pathology empowers organizations and collaborative groups to securely govern and share data, delivering best-in-class privacy and security from a cloud-based SaaS platform.
